A Very Big Video Reasoning Suite
We bet on a future that video reasoning is the next fundamental intelligence paradigm, after language reasoning, where spatiotemporal embodied world experiences could be more naturally captured.
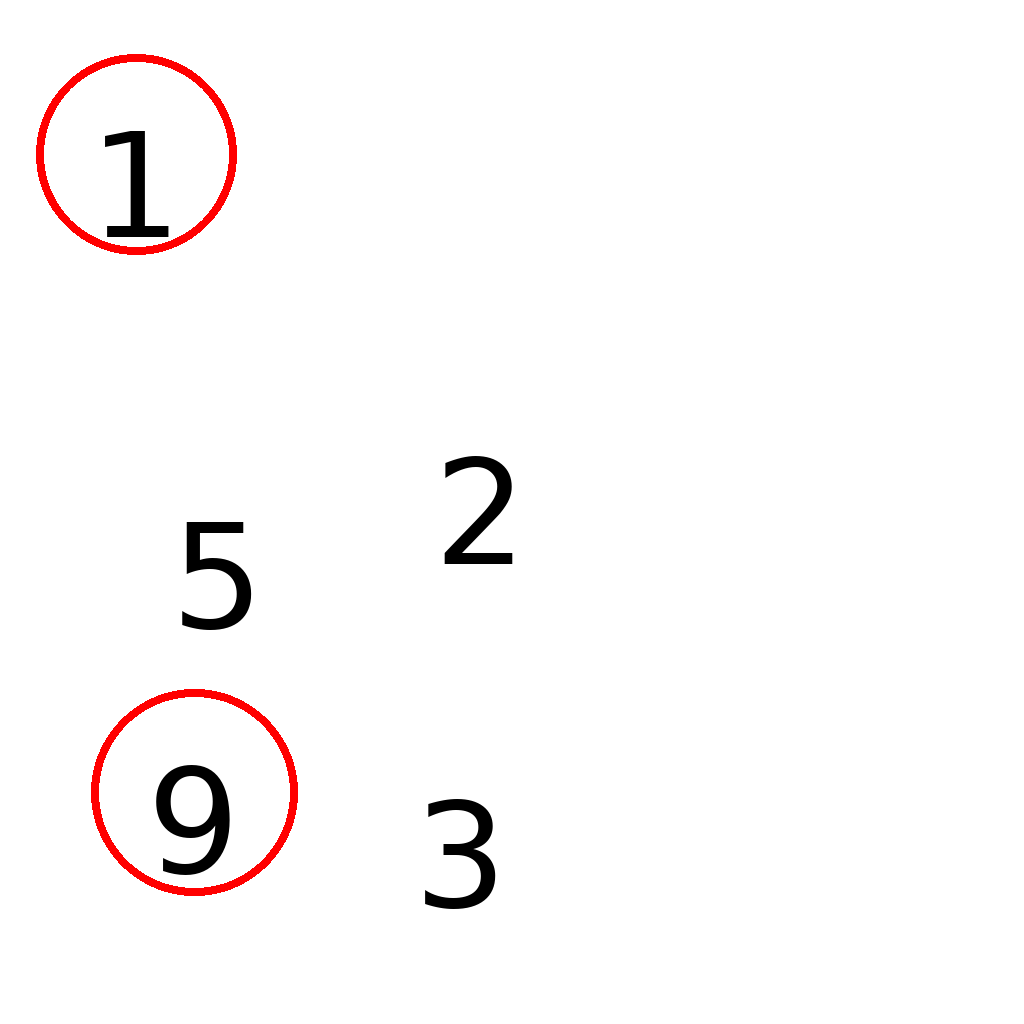
identify_one_and_nine
GitHub
Prompt
The image shows a subset of digits chosen from 1 to 9 placed in different positions.
Find digit 1 and digit 9.
Only circle digits '1' and '9'. Do not circle other digits.
Draw a red circle around each target digit.
First Frame

Last Frame
Video
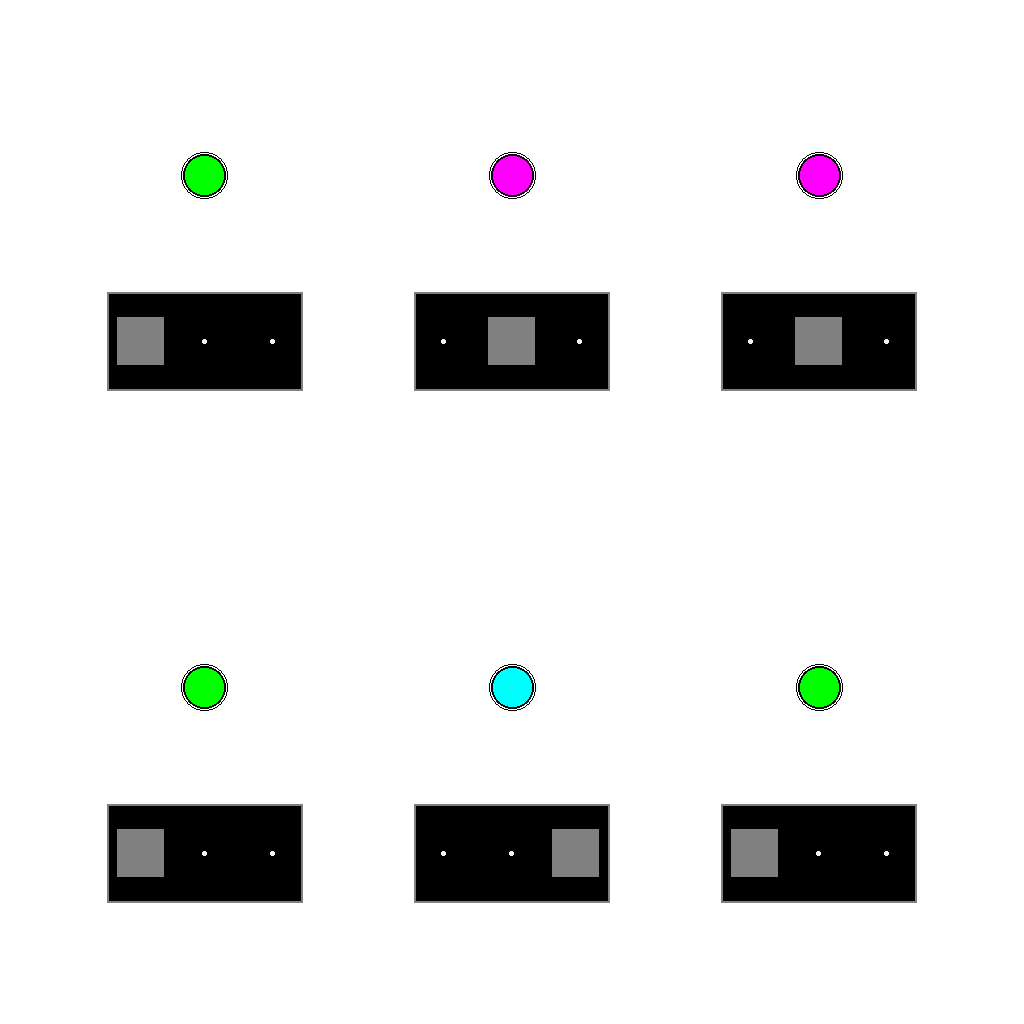
control_panel
GitHub
Prompt
The image shows a control panel with six identical control units. Each unit has a colored indicator light at the top and a control lever at the bottom that can be moved to three positions (left, middle, or right).
Observe the current control panel to infer the relationship between lever positions and light colors. Based on this inferred relationship, adjust the levers that need to be changed to make all indicator lights show yellow color.
First Frame
Last Frame

Video
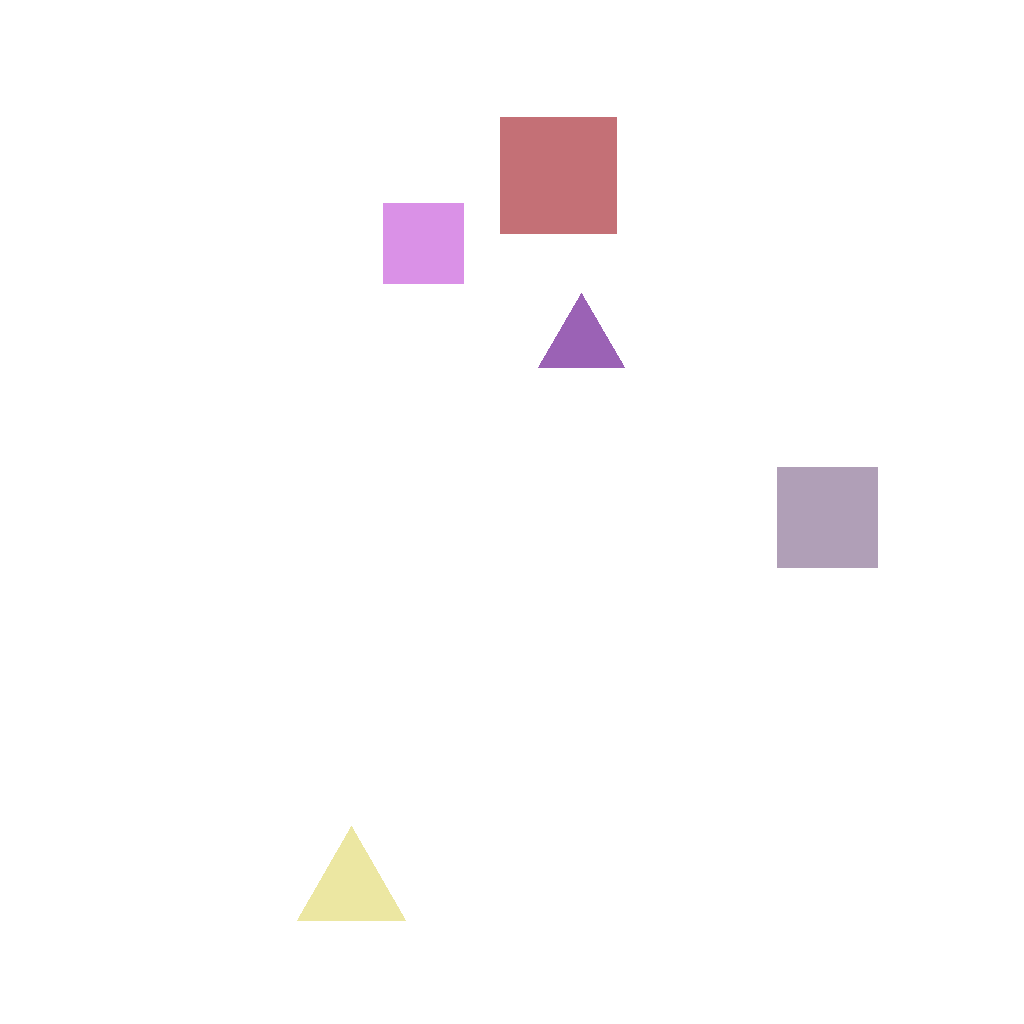
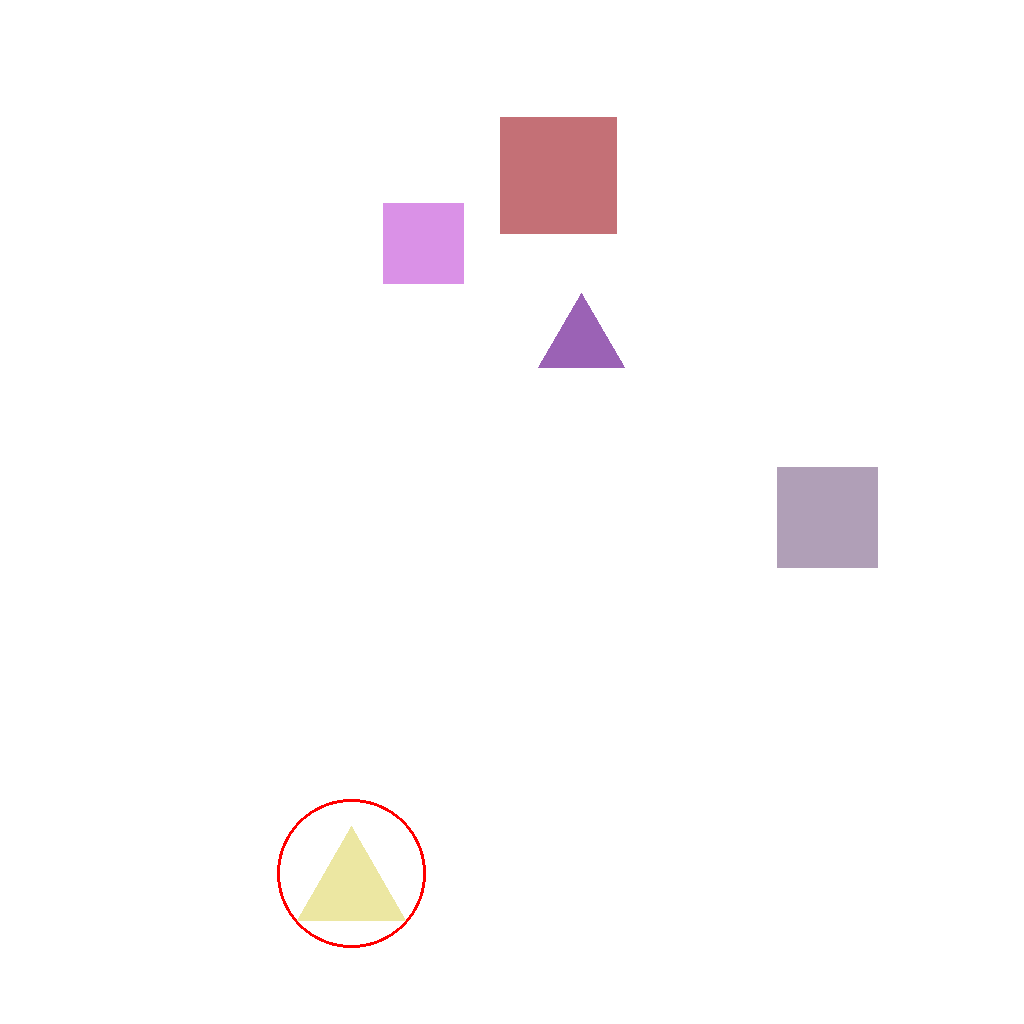
select_leftmost_shape
GitHub
Prompt
Multiple shapes are shown. Circle the leftmost one. Do not change anything else.
First Frame
Last Frame
Video
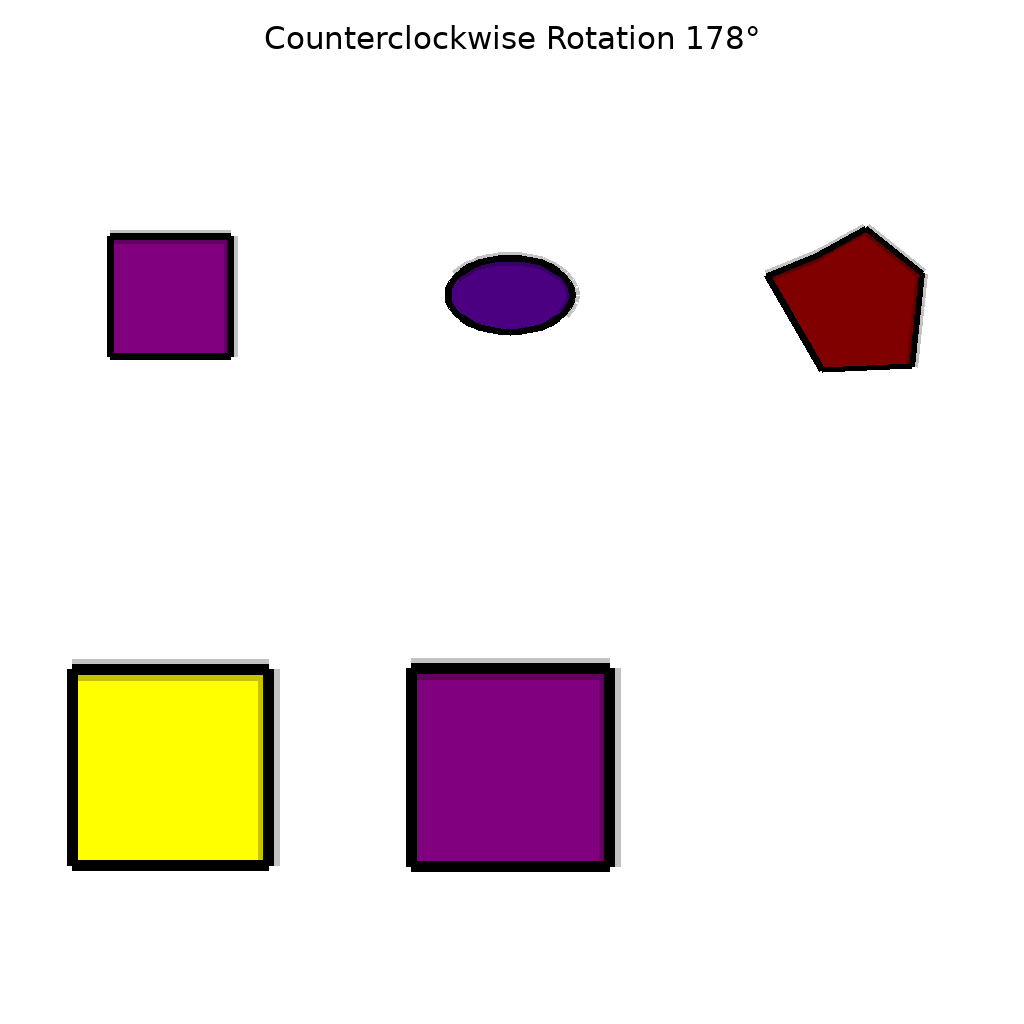
2d_object_rotation
GitHub
Prompt
The scene contains 4 2D object(s). Show them rotating clockwise by 53 degrees around their respective centroids.
First Frame
Last Frame
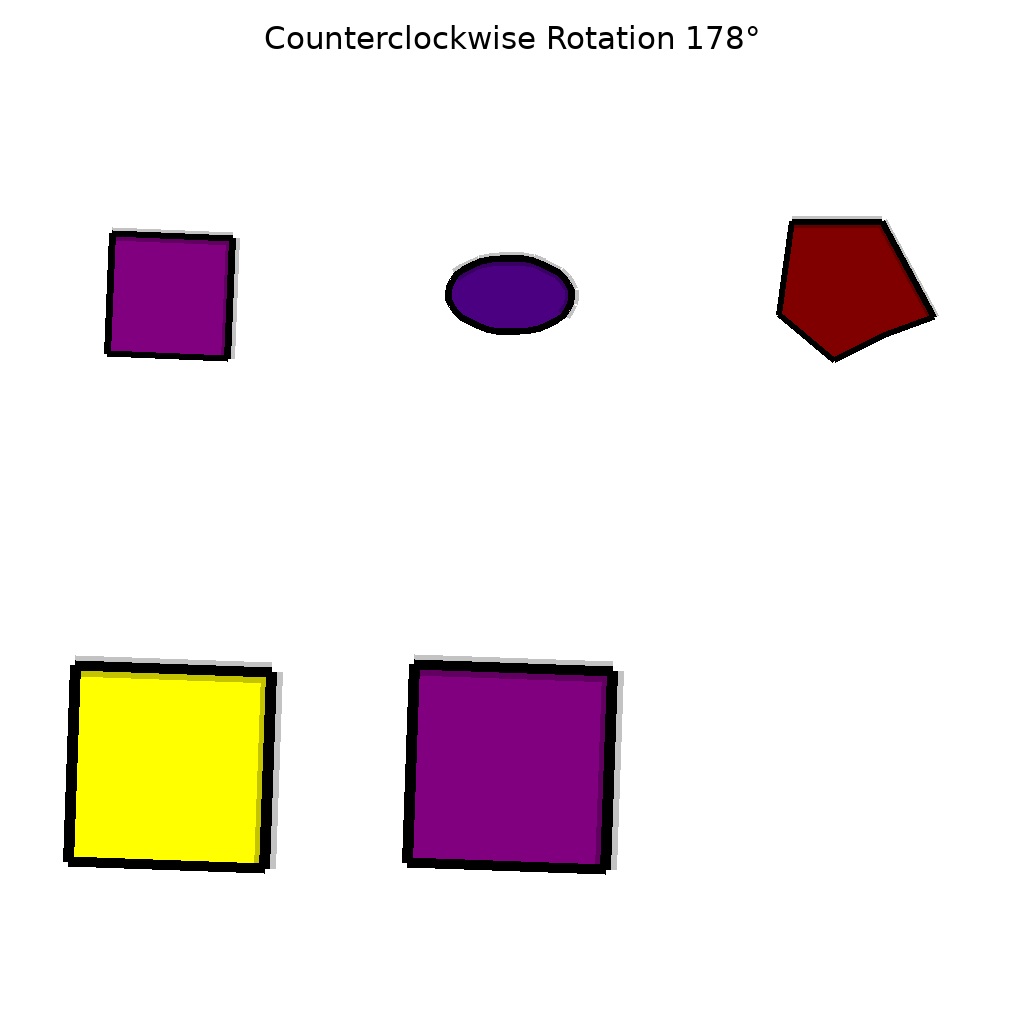
Video
select_longest_polygon_side
GitHub
Prompt
The image shows an irregular polygon with 6 sides. First compare the lengths of all polygon edges, then mark the single longest side by drawing a small circle at its midpoint. Do not change anything else. Show the complete solution step by step.
First Frame

Last Frame
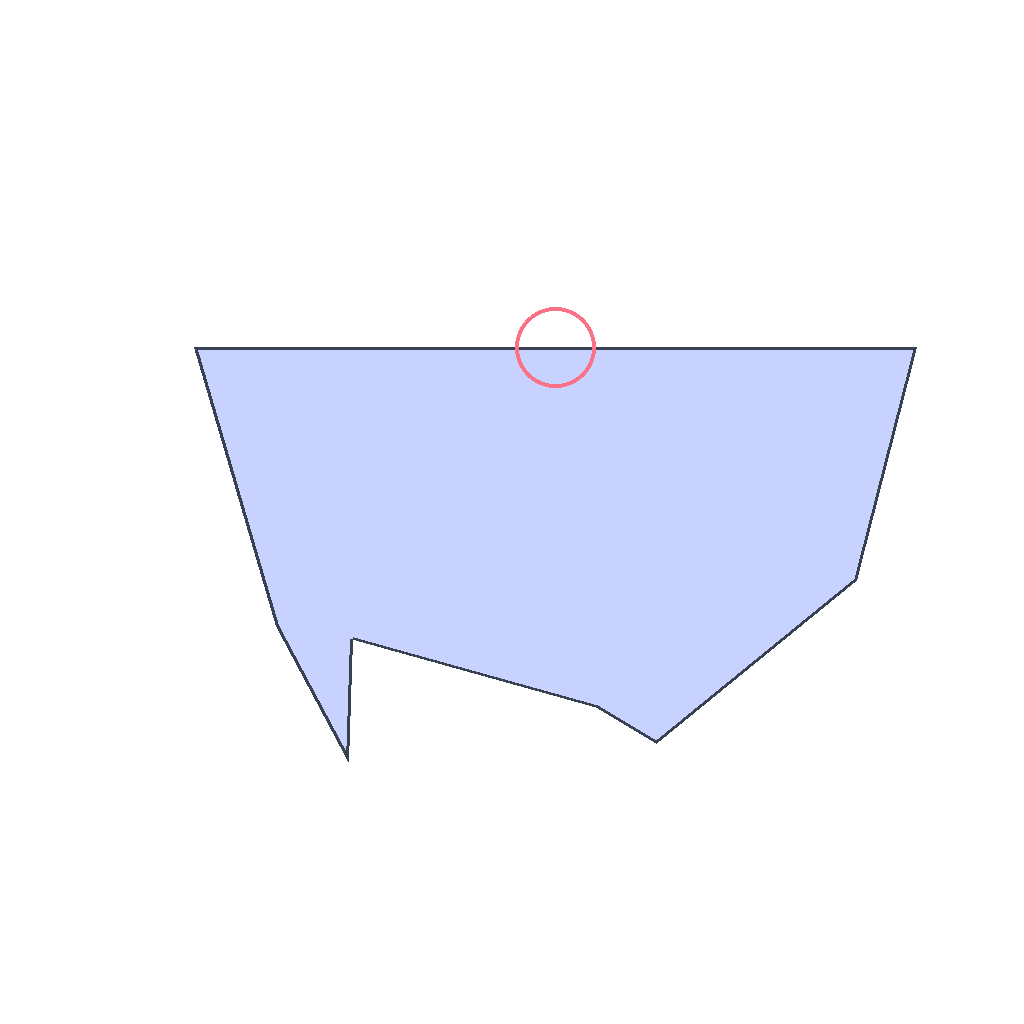
Video
Traffic Light - Samples
00
01
02
03
04
Prompt
Loading...
Ground Truth
First
Final
Model Outputs
1/
VBVR-Wan2.2
VBVR-Wan2.2
CogVideoX 1.5
Kling 2.6
LTX-2
Runway Gen-4
Sora 2
Veo 3
Wan 2.2 I2V
Hunyuan I2V
Seedance 2.0
Leaderboard
Modality
Split
Type
Category