Projects

VBVR-Wan2.2
Our video reasoning model trained on VBVR-Dataset using Wan-2.2 as the base model. Our scaling study shows concurrent performance improvements on both in-domain and out-of-domain tasks.
View Model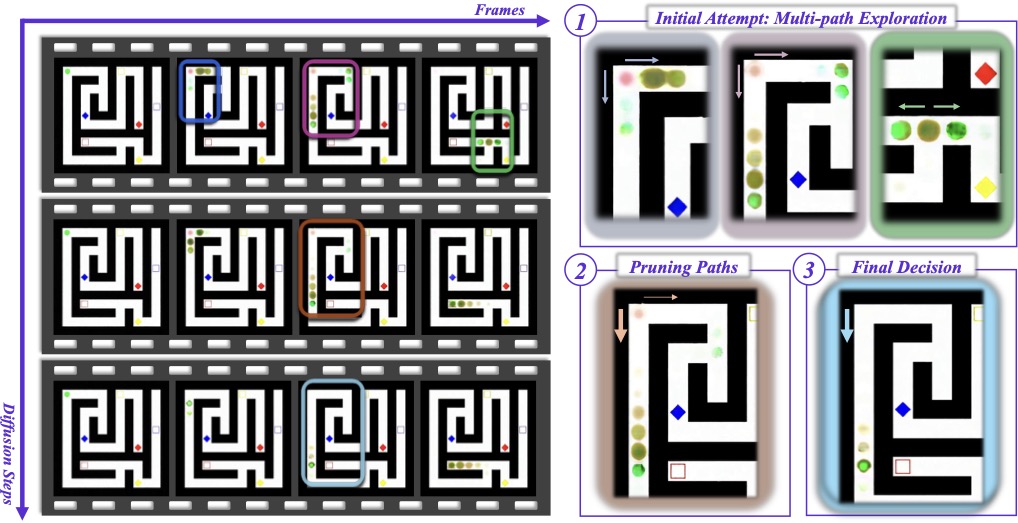
Demystifying Video Reasoning
Reasoning in video generation models emerges through diffusion denoising steps — a mechanism we call Chain-of-Steps — not through sequential frames. We document four emergent behaviors: working memory, self-correction, perception-before-action, and DiT layer specialization.
Read Paper