A Very Big Video Reasoning Suite
We bet on a future that video reasoning is the next fundamental intelligence paradigm, after language reasoning, where spatiotemporal embodied world experiences could be more naturally captured.
ball_bounces_given_time
GitHub
Prompt
A ball is placed at the initial position with a direction arrow indicating its movement direction. Simulate the ball bouncing 2 times off the boundary walls following elastic collision physics (angle of incidence equals angle of reflection). The ball stops after the 2th bounce, with its final position at the wall where the last collision occurs.
First Frame
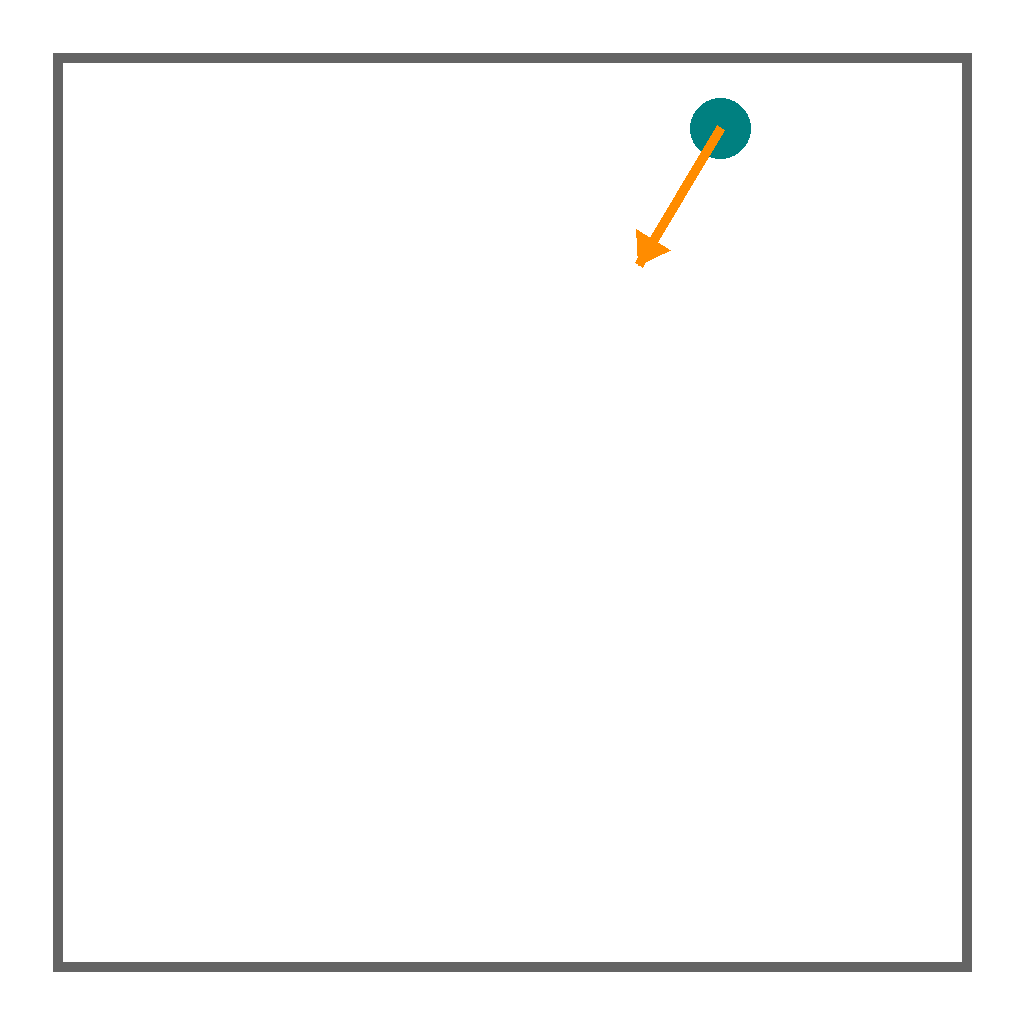
Last Frame

Video
select_next_figure_increasing_size_sequence
GitHub
Prompt
The scene has two separated areas: a top SEQUENCE area and a bottom CHOICES area. In the SEQUENCE area, the shapes are the same shape and the same color, and their sizes strictly increase from left to right. First identify the constant size step between consecutive sequence shapes, then select the one correct option (out of 4) in the CHOICES area that continues the same shape, color, and size-increase pattern. Circle the correct option and show the full process step by step.
First Frame

Last Frame

Video
maze
GitHub
Prompt
The scene shows a 15×15 grid maze with dark walls and white pathways. A green circular marker indicates the starting position, and a red flag marks the end position. Starting from the green start position, navigate through the maze by moving along the white pathways. You can move to adjacent cells (up, down, left, right) but cannot pass through the dark walls. The goal is to find and demonstrate the complete path from the green start to the red flag end position, showing each step of the journey through the maze.
First Frame

Last Frame
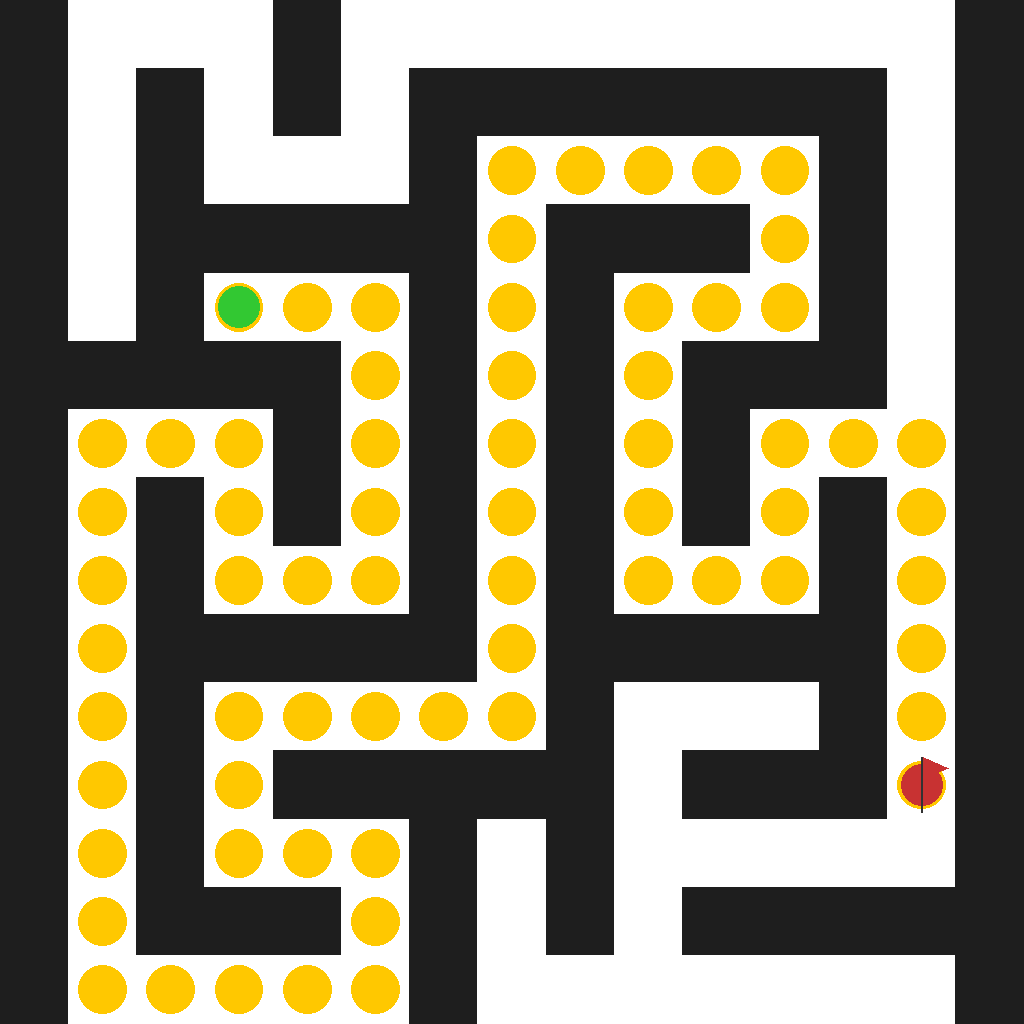
Video
rotation_puzzle
GitHub
Prompt
Solve this rotation puzzle by rotating the four squares to connect the pipe paths. Each square can be rotated 90 degrees clockwise or counterclockwise. Rotate the squares so that all pipe paths connect to form a continuous path. Keep the camera view fixed in the top-down perspective and maintain all square positions unchanged. Stop the video when all pipes are connected and the puzzle is solved.
First Frame

Last Frame

Video
draw_midpoint_perpendicular_line
GitHub
Prompt
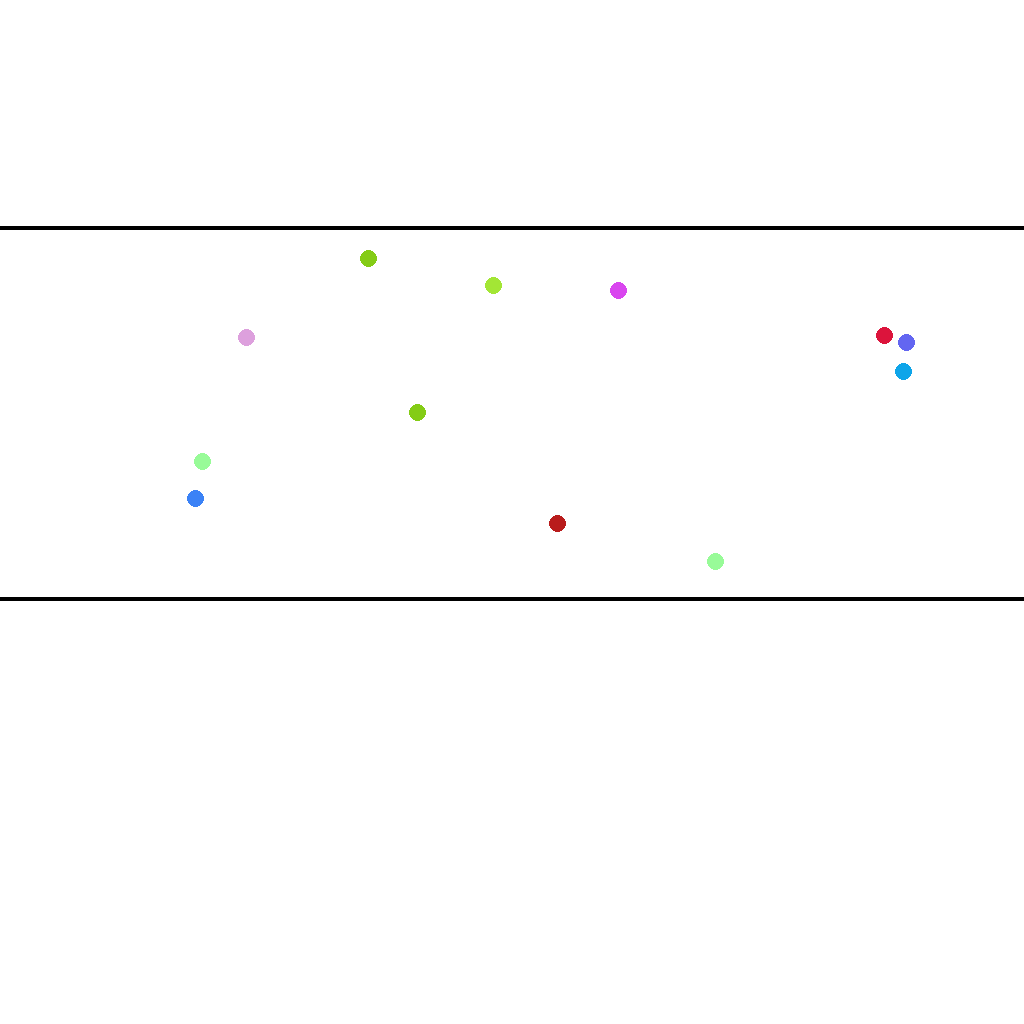
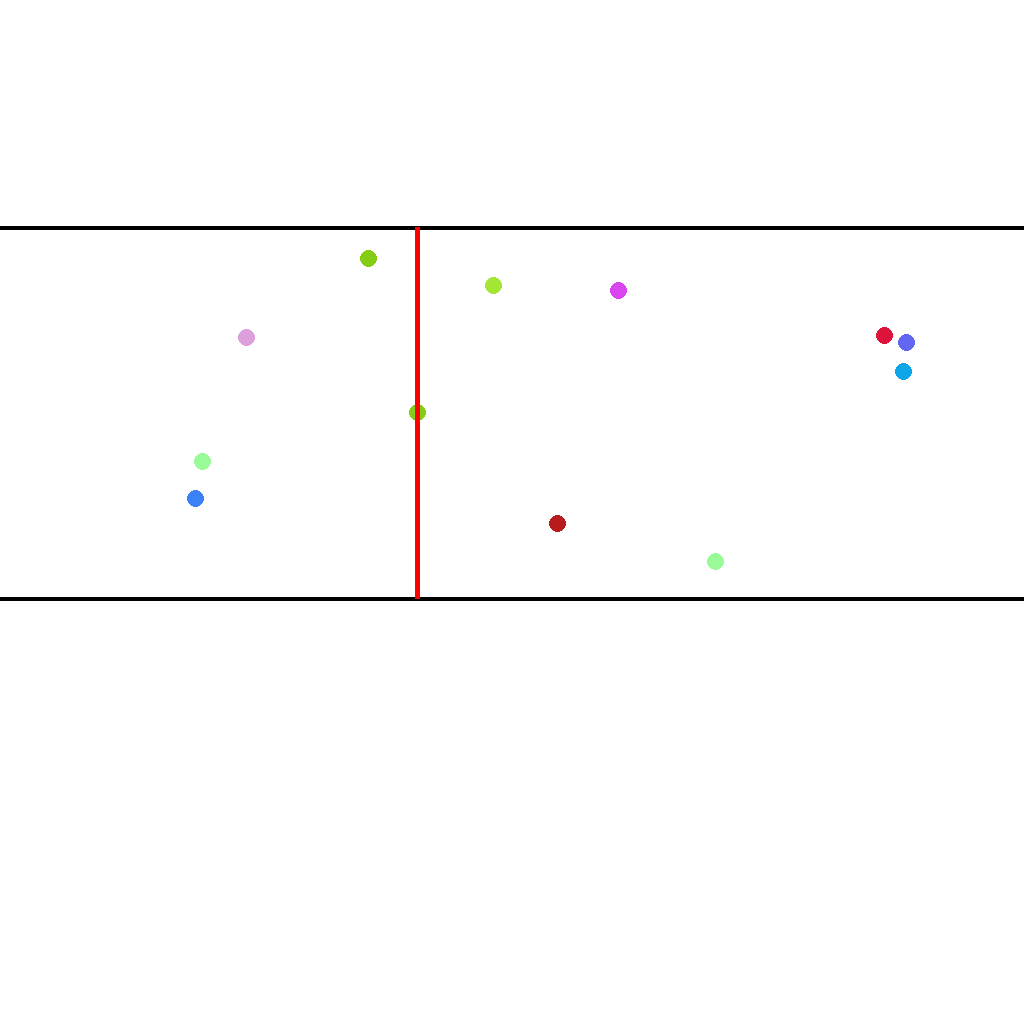
Draw a vertical red line through the middle point that is perpendicular to the horizontal parallel lines. The line should extend from the upper parallel line to the lower parallel line.
First Frame
Last Frame
Video
Domino Chain Prediction - Samples
00
01
02
03
04
Prompt
Loading...
Ground Truth
First
Final
Model Outputs
1/
VBVR-Wan2.2
VBVR-Wan2.2
CogVideoX 1.5
Kling 2.6
LTX-2
Runway Gen-4
Sora 2
Veo 3
Wan 2.2 I2V
Hunyuan I2V
Seedance 2.0
Leaderboard
Modality
Split
Type
Category